

Hi all and welcome back. This is the third and last part of the previous blog posts of backing up and restore ETCD in an OpenShift cluster using Kasten K10. I’ve already explained what is ETCD and why in some scenarios could be good to have an ETCD backup. The ETCD backup process with Kasten was also explained in the last post, so, in this post we will describe the process to restore the ETCD backup using Kasten and how to use it to restore an OpenShift cluster to a previous state.
When using Kasten we can restore the ETCD backup previously created, and use this backup to restore a Kubernetes cluster, in this OpenShift, to a previous state using the standard OpenShift procedure to restore ETCD with minor modifications. Here is important to understand that Kasten won’t revert the Kubernetes/OpenShift cluster state using the ETCD Backup, but all Kasten will do is to restore the ETCD backup file itself from the Location Profile (repository) to a location in one of the Control Plane nodes. After that you need to follow the required steps to use that backup file to revert the cluster to the desired state.
Important: Remember the RedHat Openshift Warning “Restoring to a previous cluster state is a destructive and destablizing action to take on a running cluster. This should only be used as a last resort.”
What we need:
- We need the cluster-restore.sh script provided by OpenShift with some modifications to work with the file restored by Kasten. Kasten provides a modified version of this script, which can be downloaded from the following link: https://github.com/kanisterio/kanister/blob/master/examples/etcd/etcd-in-cluster/ocp/cluster-ocp-restore.sh
- Create a namespace where the K10 restore will be executed:
- We need to create a Persistent Volume and a Persistent Volume Clain in the namespace we created in the previous step. These PV and PVC will be used to copy the ETCD backup file to the Control Plane (master) node we choose to perform the restore operations. We can use the following commands to create both resources:

- We need SSH connectivity to all master nodes (Control plane).
Restore the ETCD backup using Kasten
Now that we have all the pre-requisites, we need to restore the ETCD backup file from the Kasten Location Profile (repository) to the Control Plane node we choose as the “Restore Node” (in my case master-0). So of course the first step is to choose one of the Control plane nodes, and then we add a label to that node, so Kasten can restore the ETCD backup file to that chosen node exactly. We will use the “etcd-restore=true” label using the following command:

Why we need this label? Well, if we remember from previous post, Kasten will use a Kanister blueprint to backup and restore ETCD. As we can see bellow, the “restore” section of the Kanister blueprint uses this label as the nodeSelector to run a Pod in the Master node chosen as the Restore node (in my case master-0), including also some Tolerations to allow the Pod to run in this node (by default no Pod can be scheduled in the Master nodes). As the same blueprint describes, the pod is used to download the backup file from the object store and copy it to the /mnt/data location of the PV mapped to PVC `pvc-etcd` created previously as part of the pre-requisites. The PV’s mount path is /mnt/data on leader node where the cluster-ocp-restore.sh script would be executed.
Now, what we need to do next is to restore the ETCD backup file to the Master/Leader node using Kasten.
- In Kasten dashboard, we can go to Applications and look for the Namespace “etcd-backup” which was created for the ETCD backup as described in the previous post. We click in “restore” to chose one restore point:

- We choose one the restore points available.

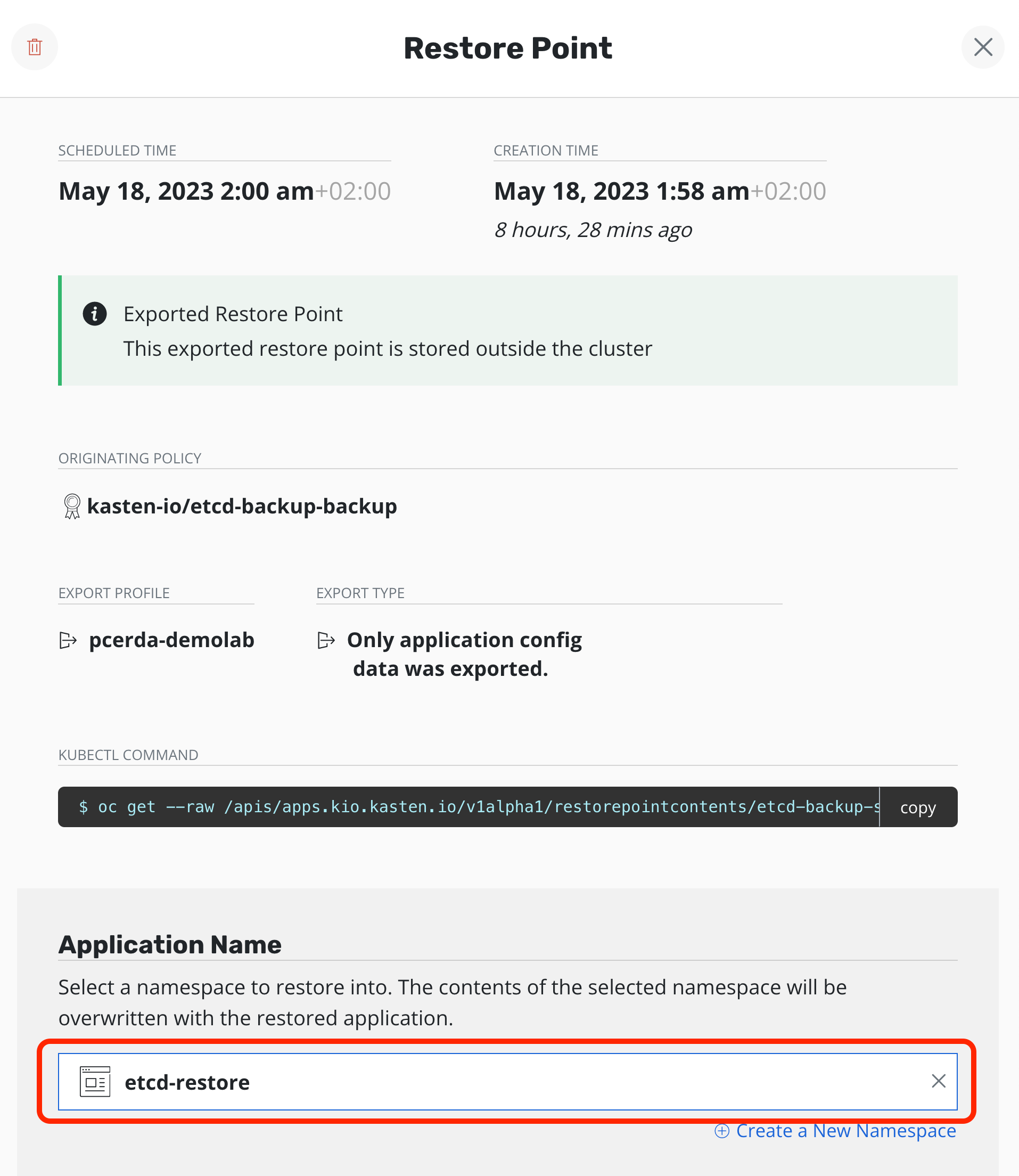
- For the restore, please select the Namespace etcd-restore created previously as part of the pre-requisites and click in Restore.
- We can go back to the Dashboard and monitor the restore task until is completed successfully.
![]()
- Now we connect via SSH to the Master node chosen as the Restore node (in my case master-0), and we check the /mnt/data location for the ETCD backup file as we can see in the following image.

Revert the OpenShift cluster state using ETCD Backup
In this point, we have restored the ETCD backup file using Kasten, and all the remaining steps to revert the cluster state will follow the standard OpenShift ETCD restore process as described in the RedHat OpenShift documentation with some minor modifications: https://docs.openshift.com/container-platform/4.13/backup_and_restore/control_plane_backup_and_restore/disaster_recovery/scenario-2-restoring-cluster-state.html
The overall ETCD restore process includes:
- Stop the static pods on any other control plane nodes but the restore node. Important: don’t stop the static pods in the restore node.
- Running the restore script “cluster-restore.sh” in the restore node (use the modified cluster-ocp-restore.sh script mentioned before instead of the standard script provided by OpenShift)
- Checking if the nodes are in the “ready” state
- Restarting the kubelet service for all of the control plane hosts, including the restore node
- Approving pending CSRs.
- Verify that the single member control plane has started successfully. From the restore node, verify that the etcd container is running.
- Deleting and recreating all of the control plane machines, with the exclusion of the one chosen for recovery purposes (restore node).
- After these machines are recreated, a new revision is forced and etcd scales up automatically.
- If you are running installer-provisioned infrastructure, or you used the Machine API to create your machines, the nodes will be re-created automatically.
- Otherwise, you must create the new control plane node using the same method that was used to originally create it.
- In a separate terminal window, log in to the cluster as a user with the
cluster-adminrole. Then force the etcd redeployment - Verifying if the nodes are up to date
- After etcd is redeployed, force new rollouts for the control plane (this should reinstall Kubernetes API to all of the nodes since an internal load balancer is used to connect the kubelet to the API server)
- Verify that all of the newly installed control plane hosts are working and joined the cluster.
The same process but a bit summarized (in case you don’t want to follow the instructions from OpenShift documentation) it’s available in Kasten documentation: https://docs.kasten.io/latest/kanister/etcd/ocp/install.html#restore
This finalizes this Blog posts series about OpenShift ETCD Backup and Restore using Kasten. As we could see:
- Restoring ETCD backup should only be used as the last resort, as it’s a very destructive and destablizing action.
- With Kasten it’s possible to design a Backup and Disaster Recovery strategy to protect all the applications and cluster-wide resources without the need of taking ETCD backups, and avoiding this cumbersome process to revert the cluster state using a ETCD backup. If you want to know more about Backup and Disaster Recovery strategies for Kubernetes using Kasten, please check this whitepaper: https://fromthearchitect.net/wp-content/uploads/2022/09/Designing_a_Kubernetes_DR_strategy.pdf
- If you still want to take ETCD backups, you can leverage Kasten to:
- Automate the ETCD backup and send it to a Location Profile (repository). Remember by default the ETCD backup is stored locally when created and it’s not automated natively (it requires a script for automation).
- Restore the ETCD backup file directly to the Master node chosen as Restore node.
- Keep multiple ETCD backups (restore points) according to the required retention policy.

[…] To continue with the restore process, please check the next post in this series: http://patriciocerda.com/?p=1487 […]
[…] ETCD? In the second part of this blog we will going to describe the process of backup and in the third part we will describe the restore ETCD in an OpenShift cluster, by using Kasten […]