

Hi all and welcome back. In this blog post I’ll talk about the need (or not) of backing up ETCD in a Kubernetes cluster, and how to do it.
Kubernetes is an orchestration tool whose tasks involve managing application container workloads, their configuration, deployments, service discovery, load balancing, scheduling, scaling, and monitoring, and many more tasks which might spread across multiple machines across many locations. Kubernetes needs to maintain coordination between all the components involved.
To achieve that coordination, Kubernetes needs a data store that can help with the information about all the components, their required configuration, state data, etc. In Kubernetes, that job is done by ETCD. ETCD is a key-value data store used to store and manage the critical information that distributed systems need for their operations. It provides a reliable way of storing the configuration data.
So, in simple words, in a Kubernetes cluster, the expected state for every Kubernetes component (Pods, Deployments, Secrets, PVCs, etc), is stored in the ETCD instance running in the Kubernetes Control Plane.
So, in theory we could just backup this ETCD instance to protect the entire cluster and being able to restore it whenever it’s necessary. This could be correct, but it’s not the best approach for a Data Protection and Disaster Recovery strategy for multiple reasons such as:
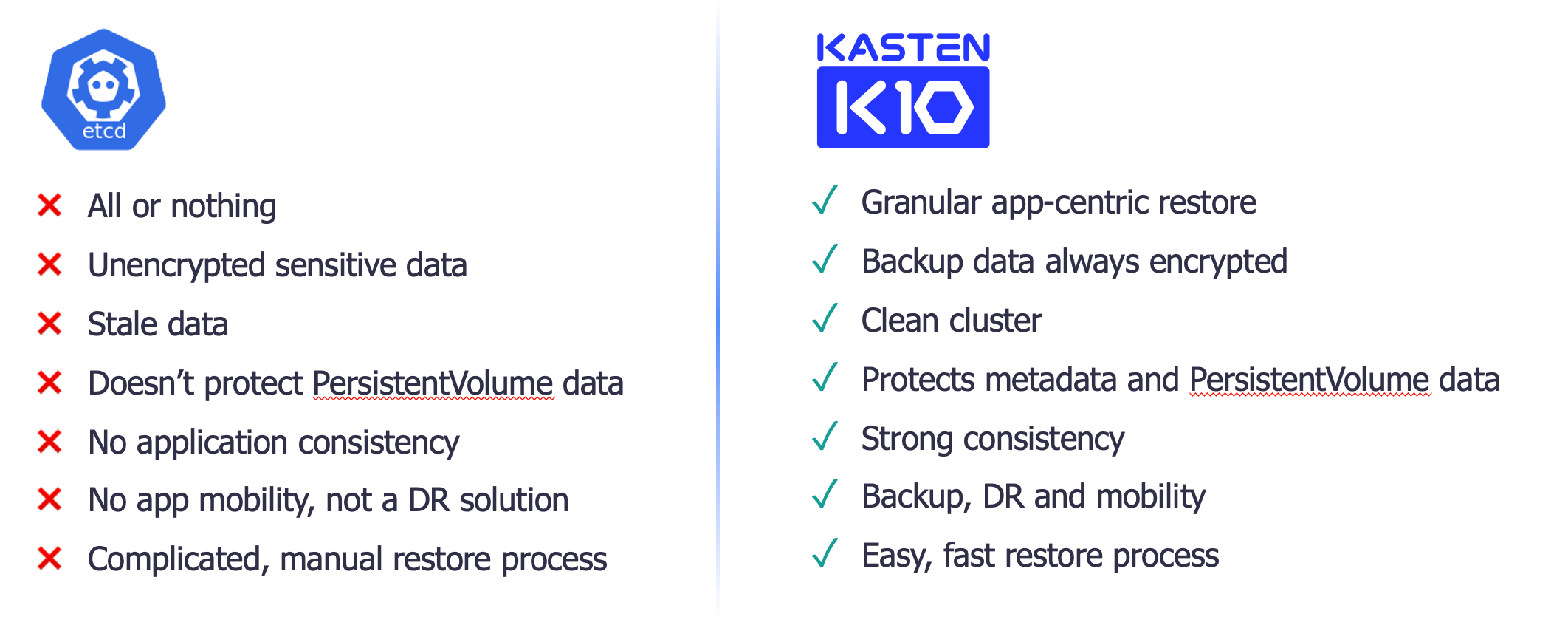
- ETCD just keeps the cluster configuration and expected state of every component, so it’s capable of restoring, for instance, all the Kubernetes workloads to a specific point in time (PIT), but remember Kubernetes workloads could be stateful, and this approach doesn’t take in consideration the persistent data of stateful applications.
- ETCD backups don’t allow for granular restore operations, so we can just restore the entire cluster or nothing at all. What if I just need to restore a single application, or a single component? Well, that is not possible.
- Automating ETCD backups can be achieve only by using scripts, which add extra complexity to this option.
Furthermore, even the RedHat OpenShift documentation provide the following warning:
You can use an etcd backup to restore your cluster to a previous state. This can be used to recover from the following situations:
- The cluster has lost the majority of control plane hosts (quorum loss).
- An administrator has deleted something critical and must restore to recover the cluster.
Restoring to a previous cluster state is a destructive and destablizing action to take on a running cluster. This should only be used as a last resort.
Using a Kubernetes native backup solution as Kasten K10, it is possible to backup all applications running in our Kubernetes clusters (alongside with the application’s data of course), and in addition it is possible to backup the cluster-wide resources like ClusterRoles or ClusterRoleBindings, and others. Kasten allows to restore entire applications, and also allows to restore individual artifacts, including cluster-wide resources.
Therefore, protecting the entire Kubernetes cluster with Kasten K10 is much more efficient than using ETCD Backups, as you can see in the following image:
Still, what if you still want to have a method to backup and restore ETCD? In the second part of this blog we will going to describe the process of backup and in the third part we will describe the restore ETCD in an OpenShift cluster, by using Kasten K10.

[…] all and welcome back. This is the second part of the previous blog post of backing up and restore ETCD in an OpenShift cluster using Kasten K10. We already explained what is ETCD and why in some […]
[…] backing up and restore ETCD in an OpenShift cluster using Kasten K10. I’ve already explained what is ETCD and why in some scenarios could be good to have an ETCD backup. The ETCD backup process with […]